

Этот текст опубликован до 24 февраля 2022 года.
Предубеждения — пугающая, но неизбежная часть нашей жизни. С одной стороны, технологии могут помочь в их преодолении: например, появляются онлайн-сообщества для персон и групп, подвергающихся дискриминации. С другой стороны, алгоритмы искусственного интеллекта могут транслировать определенные предрассудки и таким образом способствовать их закреплению и усугублению. Из-за чего алгоритм становится носителем предрассудков и дискриминационных практик и что мы можем сделать, чтобы строить более справедливые системы, объясняет художник и исследователь Денис Протопопов.
Алгоритмы легко масштабируются и позволяют автоматизировать большое количество рутинных, сложных и ответственных задач. При этом довольно высокая и часто удивляющая точность их работы создает ощущение объективности и достоверности. Отсюда логичным образом возникает соблазн передать искусственному интеллекту задачи, требующие рационального подхода. Например, машине пробуют поручить прием на работу или в университет, вынесение приговоров в суде, медицинскую диагностику и многое другое. Однако человеческие предубеждения, давно бытующие в обществе, даже в таком случае могут проявиться в решениях «объективного» алгоритма.
Можно выделить три основных фактора, из-за которых ИИ приобретает человеческую склонность к предрассудкам:
- входные данные, которые являются фундаментальной составляющей систем на основе искусственного интеллекта,
- архитектура алгоритмов,
- способность алгоритмов находить неочевидные для человека признаки.
Входные данные: bias in, bias out
Способность самостоятельно решать задачи по мере накопления опыта — главная особенность и ценность алгоритмов искусственного интеллекта. Если мы хотим обучить алгоритм распознавать рукописный текст, нам нужно подготовить десятки тысяч примеров написания различных букв. Если мы хотим создать систему для распознавания спама, нам нужна большая коллекция спам-писем; алгоритм для решения о выдаче кредита — кредитную историю сотен тысяч людей. Алгоритм для предсказания преступлений — исторические данные о задержаниях, совершенных преступлениях и приговорах. Все алгоритмы на основе искусственного интеллекта обращаются к прошлому, чтобы предсказывать события, которые произойдут в будущем.
ProPublica в своем расследовании "Machine Bias" (Машинные предрассудки) описывает практику применения автоматизированной системы COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) в различных штатах США. Алгоритм оценивает вероятность совершения подсудимым нового преступления в будущем, и как следует из ее названия, позволяет оценить возможность присвоения альтернативной меры пресечения. Судьи в некоторых штатах действительно учитывают оценки этой системы при вынесении окончательного решения.
Проверяя, какие из прогнозов системы наиболее близки к истине, журналисты из ProPublica обнаружили, что COMPAS предвзят в своем прогнозировании по отношению к темнокожим людям. Система ложно оценивала афроамериканских подсудимых как рецидивистов, а белых подсудимых считала менее склонными к повторным преступлениям. Такие прогнозы часто не имели ничего общего с уже состоявшейся реальностью.
Предвзятость по отношению к темнокожим подсудимым со стороны алгоритма объясняется предвязостью, содержавшейся в данных, на основе которых ранее принимались решения. По словам Сандры Мэйсон, профессора права из университета Пенсильвании, хотя такие системы как COMPAS были созданы, чтобы прогнозировать вероятные преступления, на самом деле они предсказывают только факт ареста. Так происходит, потому что данные, на которых строится система, почти не содержат информацию о совершенных преступлениях. К примеру, по некоторым делам люди были ложно обвинены; другие — не привели к заключению; часть арестов и вовсе были ошибочны.
Статистика показывает: темнокожие люди в США оказываются под арестом чаще, чем белые люди. При этом количество преступлений, совершенных первыми и вторыми, примерно равно. Мэйсон ссылается на отчет ACLU, согласно которому и темнокожие, и белые люди употребляют марихуану более-менее в одинаковом объеме, однако именно первые чаще всего оказываются под арестом из-за этого.
Искусственный интеллект на различных этапах судопроизводства используют не только в США. В Китае эта технология используется для оптимизации обработки и подготовки различных документов, стенографии и идентификации личности. В России ИИ тоже используетсядля подготовки документов и помощи при формировании судебных приказов по взысканию денежных средств. А эстонское министерство юстиции заинтересовано в использовании автоматизированных судов для рассмотрения мелких исков до 7 000 евро.
Однако кейс с применением системы COMPAS, описанный ProPublica, — пожалуй, самый громкий пример опасного дизайна системы искусственного интеллекта для участия в судебных разбирательствах. На это расследование, например, ссылается Европейская этическая хартия об использовании искусственного интеллекта в судебных системах, принятая в 2018 году Советом Европы. Она указывает на предрассудки, которые могут проявляться в системах ИИ: например, на тот факт, что история поведения группы людей, по сути, будет определять судьбу отдельно взятого человека.
Есть интересный кейс и из российской практики: создатели проекта «Алгоритм Света» проанализировали тексты уголовных дел, связанных с домашним насилием. В итоге они создали программу, которая по тексту судебного приговора об убийстве женщины, определяла, подвергалась ли жертва домашнему насилию. При этом создатели «Алгоритма Света» поясняют, как такой механизм помогает оценить реальный масштаб проблемы: в официальной статистике о домашнем насилии указываются только люди, которые юридически являются членами семьи; в ней не учитываются партнеры, не состоящие в браке, бывшие супруги и т. д. Кроме того, в статистике содержатся только уголовные, а не административные дела.
1000 и 1 категория

Упомянутые выше кейсы касаются только одной из проблем, связанных с некорректно подготовленными данными для алгоритмов искусственного интеллекта, и только одного случая применения технологии. Прямо сейчас где-то собираются и создаются наборы данных для обучения систем ИИ — которые впоследствии будут использоваться для большого числа самых разных задач. Такие системы впечатляюще успешно распознают объекты на картинках, лица людей и речь, генерируют тексты и делают много еще чего.
Вот один из примеров. ImageNet — это большой датасет, содержащий 14 миллионов изображений, относящихся к 20 тысячам категорий. Благодаря этому набору данных, улучшенным вычислительным способностям и подбору подходящего алгоритма в начале 2010-х случился прорыв в компьютерном зрении. Эта область искусственного интеллекта ставит своей целью создание машин, которые могут распознавать визуальные образы и генерировать новые изображения. Теперь алгоритмы умеют успешно распознавать и выделять один или несколько объектов на изображении. Создается ощущение, что проблема решена: компьютер способен определить, что перед ним находится. Однако исследователь Кейт Кроуфорд и художник Тревор Паглен в своем эссе утверждают, что задача научить компьютер описывать, что он видит перед собой, всегда будет сопряжена с рядом этических и политических проблем. И дело снова в данных.
Кроуфорд и Паглен называют свой метод изучения датасетов «археологией». Исследователи изучают содержимое баз данных и пытаются понять, как они устроены. Если мы, как и авторы, применим метод археологии к ImageNet, то увидим ничем не примечательные категории: различные виды транспорта, фруктов, ягод, мебели, природных явлений и тысячи других. Причем все категории сгруппированы иерархически: одна категория содержит несколько других и так далее.
Среди описаний людей, которые выделяют авторы эссе, в датасете можно найти: «мужчина», «женщина», «отец», «бисексуал», «бойскаут», «гермафродит», «наркоман», «парикмахер», «алкоголик», «шизофреник», «слабак», «нейробиолог», «проститутка», «неудачник», «деревенщина», «мулат», «большевик», «антисемит» и десятки других. Причем каждой из категорий соответствуют определенные изображения.
Откуда вообще в ImageNet возникли такие категории? Таксономия ImageNet опирается на WordNet: базу данных для классификации слов, созданную в 1980-х. Именно оттуда в ImageNet попали оскорбительные и субъективные категории. Сейчас категории и изображения, описывающие людей, просто исключены из текущей версии набора данных ImageNet, однако в интернете все еще встречаются старые варианты, а где-то используются алгоритмы, обученные на этой дискриминирующей версии.
Этот кейс приводит нас к выводу о том, что наборы данных, составленные для алгоритмов искусственного интеллекта, несмотря на кажущуюся объективность, являются продуктом конкретных решений. Причем за их принятием стояло ограниченное число людей, которые однажды добавили категории «клептоман», «гермафродит», «большевик» и снабдили их иллюстрациями. Это лишь десятки из 20 тысяч категорий, которые, тем не менее, могут проскользнуть в системы управления беспилотным транспортом или видеонаблюдения и повлиять на действия, совершаемые с опорой на эти технологии.
Помимо того, что в наборы данных могут попадать спорные категории, оттуда порой исчезает и необходимая информация. Вот наглядный пример: когда компания Amazon запустила систему рекрутинга на основе искусственного интеллекта в середине 2010-х, обнаружилась странная закономерность — оценки женщин были ниже. Проблема снова была в данных: алгоритм обучался на резюме, которые приходили в Amazon в течение последних десяти лет. Подавляющее большинство заявок было от кандидатов-мужчин, которых, к тому же, приглашали на работу в компанию чаще, чем женщин. Конечно, основываясь на таких данных, алгоритм Amazon предпочел мужчин. Отбраковывались резюме, содержащие слова «женский»: например, «капитан женского шахматного клуба», или «выпускницы женских колледжей». В итоге, компания отказалась от использования искусственного интеллекта при приеме наработу.
Аналогичные проблемы могут возникнуть при использовании искусственного интеллекта для оценки абитуриентов. Такие системы внедряют, чтобы избавиться от предубеждений на этапе приемных кампаний. Однако мы уже знаем: чтобы научить алгоритм советовать и предсказывать, мы должны показать ему информацию, на которой он будет делать свои выводы. А если проблема предвзятости при приеме в университет существует, то она отразится и на результатах. В нью-йоркских колледжах несмотря на относительно пропорциональное число заявок на поступление от темнокожих и белых студентов, среди зачисленных подавляющее большинство составляют именно белые. Также в США число женщин, получающих образование в области компьютерных наук, только снижается: с 37% в 1980-х до 18% в 2016 году. Такая динамика легко может впоследствие отразиться на логике алгоритма, который будет принимать решения о зачислении в университет.
Архитектура AI-систем
Печальная статистика гендерного состава студентов, изучающих компьютерные науки, отражается и на индустрии: мужчины занимаютот 77 до 83 процентов технических позиций в Apple, Facebook, Microsoft, Google и General Electric. Авторы книги «The Smart Wife» Йоланда Стренджерс и Дженни Кеннеди отмечают: среди разработчиков и менеджмента мало не только женщин, но также темнокожих и квир-людей. Из-за этого в IT-компаниях создают целые системы на основе искусственного интеллекта, воспроизводящие и укрепляющие существующие предрассудки.
Как следует из названия книги, авторы изучают феномен «smart wife» — так они концептуализируют голосовых ассистентов (Alexa, Siri, Google Home). Речь идет об устройствах и виртуальных агентах, которые по умолчанию наделены стереотипными женскими характеристиками — в частности, они созданы, чтобы помогать в ведении домашнего хозяйства. Такие ассистенты создаются в основном инженерами-мужчинами — и мужчины же являются инициаторами установки систем умного дома. Авторы книги выступают за поиск подходов в создании умных ассистентов, которые не будут усиливать существующие гендерные порядки.
Дополнительные сложности связаны с самим принципом работы AI-систем: они понимают только числа. Это усложняет работу с такими неустойчивыми категориями как гендерная и сексуальная идентичность. Кроме того, возникает соблазн подобрать конкретные признаки во внешности и поведении, которые бы соответствовали этим искусственно собранным идентичностям.
Кризис разнообразия в данных также негативно отражается на качестве алгоритмов распознавания лиц, например, темнокожих людей. Разные компании ищут способы решения этой проблемы. Так, IBM представила в 2019 году набор данных «Разнообразие в лицах». Он состоит из десятков тысяч фотографий людей с разным цветом кожи. Правда, к каждому изображению прилагается информация о симметрии лица и измерения черепа. Уже упомянутые выше Кроуфорд и Паглен считают, что такой подход не помогает избавиться от предрассудков, а только усиливает их. Авторы сравнивают такие данные с практикой краниометрии — то есть, измерения черепа, — которая использовалась в 19-20 веках.
Неочевидные признаки
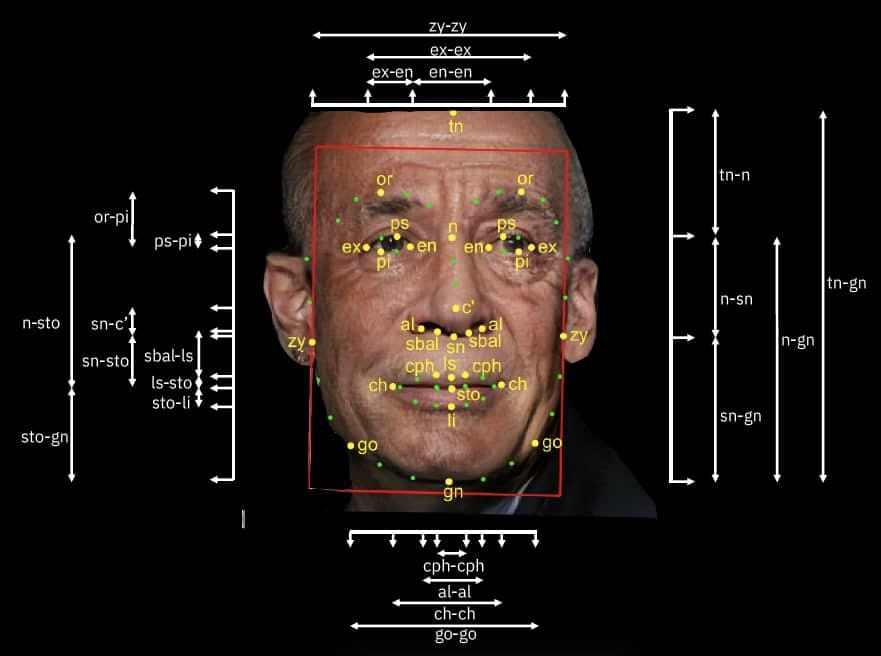
У систем искусственного интеллекта, в частности компьютерного зрения, есть одна интересная особенность — они могут самостоятельно находить в изображениях признаки, позволяющие отнести картинку к определенному классу. Программисту не нужно вручную объяснять компьютеру причины, по которым картинки с кошками отличаются от картинок с собаками. Достаточно лишь собрать две папки: одну — с кошками, другую — с собаками, а алгоритм сам научится находить признаки и сортировать изображения, которые он прежде не видел. Причем признаки, которые находит машина, часто бывают непонятными для человека, а некоторые мы даже не в состоянии различить.
Профессор из Стэнфорда Михал Косински совместно со своим коллегой Йилун Уэнгом в статье 2017 года описал, что алгоритм на основе сверточных нейронных сетей (архитектура нейронных сетей, изначально нацеленная на эффективное распознавание изображений — прим. сверхновой) может определить сексуальную идентичность человека по его лицу. При этом не существует известных объективных признаков, которые позволяли бы сделать это человеческому глазу. Однако само исследование можно раскритиковать за упрощение категории сексуальной идентичности и ее редукции до «гомосексуальной» и «гетеросексуальной». Сама такая ситуация распознавания создает патологизацию: статус аномалии приписывается признакам, которые, на самом деле, никак не связаны с сексуальной идентичностью. Использование такой системы, несмотря на ее ограниченность с точки зрения спектра идентичностей, может поставить в реальную опасность людей в тех странах, где квир-персоны маргинализированы.
В другой статье, вышедшей летом 2021 года, описывается, что системы на основе искусственного интеллекта могут распознавать этническую принадлежность пациента по его медицинским снимкам: рентгену и компьютерным томографиям. При этом человек сделать этого не может. Исследователи проверили возможные физиологические признаки этнической принадлежности и оказалось, что для ИИ они не играют никакой роли при прогнозировании. Кроме того, точность распознавания остается высокой даже на сильно зашумленных снимках или если часть лица скрыта. Уже известны случаи, когда искусственный интеллект научился определять переломы на рентгеновских снимках не глядя на саму кость, а определяя, в какой больнице был сделан снимок: это можно сделать из-за определенных характеристик при настройке аппарата. Все эти примеры могут создавать сложности при работе с пациентами.
Что с этим делать?
Предрассудки в алгоритмах искусственного интеллекта изучаются исследователями и практиками. Создаются различные библиотеки и инструменты для справедливого (Fairness) машинного обучения, которые позволяют убедиться, что на работу алгоритма не влияют пол, этничность, сексуальная идентичность, вероисповедание и другие признаки. Например, библиотеки AI Fairness 360 от IBM и Fairlearn. Они показывают, какие признаки могут повлиять на объективность результата. Однако такой подход, по сути, изолирующий отдельные признаки, не всегда актуален. Во-первых, уменьшение размеров набора данных влияет на его точность. Во-вторых, могут существовать другие признаки, которые коррелируют с теми, что чаще приводят к предрассудкам, но не подлежат исключению: информация о месте жительства, семейном положении, образовании и многом другом. Кроме того, в уже упомянутой статье Сары Мэйсон говорится, что исключение отдельных признаков из данных, в частности этничности, не решает проблему: игнорирование этнической принадлежности означает игнорирование расизма. Знание об институциональном расизме как раз крайне важно учитывать при проектировании систем ИИ.
Вряд ли можно раз и навсегда избавиться от предрассудков в системах искусственного интеллекта, ведь людей без предрассудков также не существует. Меньшее и самое реалистичное, что мы можем сделать для решения этой проблемы — включать в разработку систем на основе искусственного интеллекта группы людей, которые меньше всего в них представлены. На это нацелены такие инициативы как Black in AI и Queer in AI, работающие над образовательными проектами и поиском грантов для своих участников.
Сейчас для многих людей искусственный интеллект является ничем иным, как черной коробкой, при этом совершенно объективной и непредвзятой. И как ни парадоксально, чем более распространенной становится технология, тем меньше мы знаем о принципах ее работы. Крайне важно уже само осознание того, что алгоритмы и данные субъективны и могут быть носителями предрассудков. А понимание принципов работы искусственного интеллекта позволяет сэкономить время, которое требуется для создания более инклюзивных и справедливых систем.



